from dataclasses import dataclass
@dataclass
class AlignedToken:
ocr: str # String in the OCR text (excluding aligmnent characters)
gs: str # String in the gold standard (excluding aligmnent characters)
ocr_aligned: str # String in the aligned OCR text (including aligmnent characters)
gs_aligned: str # String in the aligned GS text (including aligmnent characters)
start: int # The index of the first character in the OCR text
len_ocr: int # The lentgh of the OCR stringSome years ago, I did a project with the Dutch National Library on OCR post-correction. I wanted to investigate the potential of Deep Learning for correcting OCR errors in text. For various reasons, we never got very good results. Around the same time, two competitions on post-OCR text correction were organized at the ICDAR conference (2017 and 2019). I remained interested in the problem and started working on reproducing the competition results in my free time.

The competition divided the challenge of OCR post-correction into two tasks:
- Detection
- Correction
This post is about my first experiences with solving the detection task. The paper about the results contains very brief descriptions of the competitors’ solutions, which makes it hard to reproduce their models. The paper states that the winner used multilingual BERT with CNN layers for recognizing tokens with OCR mistakes. For simplicity, I decided to start with training a simpler BERT for token classification model.
The data
The competition dataset consists of (historical) newspaper data in 10 languages. Each text file contains three lines, e.g.,
[OCR_toInput] This is a cxample...
[OCR_aligned] This is a@ cxample...
[ GS_aligned] This is an example.@@The first line contains the ocr input text. The second line contains the aligned ocr and the third line contains the aligned gold standard (GS). @ is the aligment character and # represents tokens in the OCR that do not occur in the gold standard (noise).
Task 1 of the competition is about finding tokens with OCR mistakes. In this context, a token refers to a string between two whitespaces. The goal of this task is to predict the position and length of OCR mistakes. I created a Python library called ocrpostcorrection that contains functionality for doing OCR postcorrection, including converting the ICDAR dataset into a Hugging Face dataset with ‘sentences’ of a certain length. This notebook contains the code used to create the dataset. I will now explain the most important steps.
First, a text is divided into aligned tokens by splitting the aligned OCR and GS on matching whitespaces. The ocrpostcorrection library contains a dataclass AlignedToken which is used to store the results:
The tokenize_aligned function is used to divide an input text into AlignedTokens.
from ocrpostcorrection.icdar_data import tokenize_aligned
tokenize_aligned('This is a@ cxample...', 'This is an example.@@')[AlignedToken(ocr='This', gs='This', ocr_aligned='This', gs_aligned='This', start=0, len_ocr=4),
AlignedToken(ocr='is', gs='is', ocr_aligned='is', gs_aligned='is', start=5, len_ocr=2),
AlignedToken(ocr='a', gs='an', ocr_aligned='a@', gs_aligned='an', start=8, len_ocr=1),
AlignedToken(ocr='cxample...', gs='example.', ocr_aligned='cxample...', gs_aligned='example.@@', start=10, len_ocr=10)]The OCR text of an AlignedToken may still consist of multiple tokens. This is the case when the OCR text contains one or more spaces. To make sure the (sub)tokenization of a token is the same, no matter if it was not yet tokenized completely, another round of tokenization is added. Using the get_input_tokens function, every AlignedToken is split on whitespace. Each subtoken is stored in the InputToken dataclass:
from dataclasses import dataclass
@dataclass
class InputToken:
ocr: str # OCR text
gs: str # GS text
start: int # character offset in the original OCR text
len_ocr: int # length of the OCR text
label: int # Class label: [0, 1, 2]This dataclass also adds the class labels. There are three classes:
- 0: No OCR mistake
- 1: Start token of an OCR mistake
- 2: Inside token of an OCR mistake
This example code shows how an AlignedToken is divided into inputTokens:
from ocrpostcorrection.icdar_data import AlignedToken, get_input_tokens
t = AlignedToken('Long ow.', 'Longhow.', 'Long ow.', 'Longhow.', 24, 8)
print(t)
for inp_tok in get_input_tokens(t):
print(inp_tok)AlignedToken(ocr='Long ow.', gs='Longhow.', ocr_aligned='Long ow.', gs_aligned='Longhow.', start=24, len_ocr=8)
InputToken(ocr='Long', gs='Longhow.', start=24, len_ocr=4, label=1)
InputToken(ocr='ow.', gs='', start=29, len_ocr=3, label=2)The output produced by this code is:
AlignedToken(ocr='Long ow.', gs='Longhow.', ocr_aligned='Long ow.', gs_aligned='Longhow.', start=24, len_ocr=8)
InputToken(ocr='Long', gs='Longhow.', start=24, len_ocr=4, label=1)
InputToken(ocr='ow.', gs='', start=29, len_ocr=3, label=2)A text can be tokenized by combining the tokenize_aligned and get_input_tokens functions. Texts are stored in another dataclass:
from dataclasses import dataclass
@dataclass
class Text:
ocr_text: str # OCR input text
tokens: list # List of AlignedTokens
input_tokens: list # List of InputTokens
score: float # Normalized editdistance between OCR and GS textA text file can be tokenized using the function process_text:
from pathlib import Path
from ocrpostcorrection.icdar_data import process_text
in_file = Path('example.txt')
text = process_text(in_file)which results in the following instance of the Text dataclass:
Text(ocr_text='This is a cxample...',
tokens=[AlignedToken(ocr='This', gs='This', ocr_aligned='This', gs_aligned='This', start=0, len_ocr=4),
AlignedToken(ocr='is', gs='is', ocr_aligned='is', gs_aligned='is', start=5, len_ocr=2),
AlignedToken(ocr='a', gs='an', ocr_aligned='a@', gs_aligned='an', start=8, len_ocr=1),
AlignedToken(ocr='cxample...', gs='example.', ocr_aligned='cxample...', gs_aligned='example.@@', start=10, len_ocr=10)],
input_tokens=[InputToken(ocr='This', gs='This', start=0, len_ocr=4, label=0),
InputToken(ocr='is', gs='is', start=5, len_ocr=2, label=0),
InputToken(ocr='a', gs='an', start=8, len_ocr=1, label=1),
InputToken(ocr='cxample...', gs='example.', start=10, len_ocr=10, label=1)],
score=0.2)The next step is processing the entire dataset. This can be done with the generate_data function. The ouptut of this function consists of a dictionary containing <file name>: Text pairs and a pandas DataFrame containing metadata. For each file, the metadata contains file name, language, score (normalized editdistance), and the numbers of aligned and input tokens:
| language | file_name | score | num_tokens | num_input_tokens | |
|---|---|---|---|---|---|
| 0 | SL | SL/SL1/29.txt | 0.463415 | 7 | 7 |
| 1 | SL | SL/SL1/15.txt | 0.773294 | 155 | 246 |
| 2 | SL | SL/SL1/114.txt | 0.019256 | 268 | 272 |
The train set consists of 11662 text files. The mean number of InputTokens is 269.51, with a standard deviation of 200.61. The minimum number of InputTokens is 0 and the maximum 3068. The histogram below shows the distribution of the number of InputTokens. Most texts have less than 250 InputTokens and there are some very long texts.
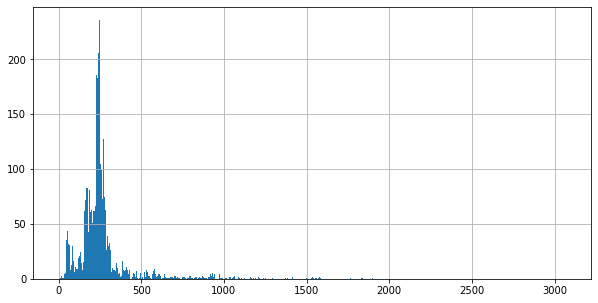
The mean normalized editdistance between OCR and GS text is 0.21, with a standard deviation of 0.13. The minimum is 0.00 and the maximum is 1.00. Smaller distances are better (less OCR mistakes). The distribution of normalized editdistance shows two peaks; one close to zero and one between 0.2 and 0.3. Most texts have a low editdistance. This means that most texts should be of high enough quality to be able to learn from.
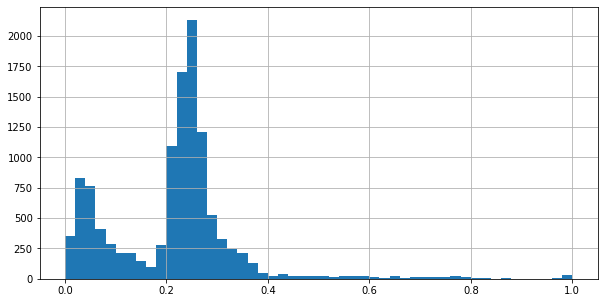
The ICDAR dataset consists of a train and test set. For validation, I split off 10% of the texts from the train set, stratified on language.
Because BERT has a limit on input length and the length of the texts vary, the texts are split up in smaller sequences. As an approximation of sentence length, for this first experiment, I chose a sequence length of 35 tokens (with an overlap of 5 tokens). The generate_sentence function returns sequences of a certain length and overlap, given the metadata DataFrame and dictionary of Text instances.
The sequences are returned as pandas DataFrame, which can be converted to a Hugging Face Dataset using the Dataset.from_pandas() method. The first two ‘sentences’ in the train set look like:
{
'key': 'FR/FR1/499.txt',
'start_token_id': 0,
'score': 0.0464135021,
'tokens': ['Johannes,', 'Dei', 'gratia,', 'Francorum', 'rex.', 'Notum', 'facimus', 'universis,', 'tam', 'presentibus', 'quam', 'futuris,', 'nobis,', 'ex', 'parte', 'Petri', 'juvenis', 'sentiferi', 'qui', 'bene', 'et', 'fideliter', 'in', 'guerris', 'nostris', 'nobis', 'servivit', 'expositum', 'fuisse,', 'qod', 'cum', 'ipse,', 'tam', 'nomine', 'suo'],
'tags': [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0],
'language': 'FR'
},
{
'key': 'FR/FR1/499.txt',
'start_token_id': 30,
'score': 0.0204918033,
'tokens': ['cum', 'ipse,', 'tam', 'nomine', 'suo', 'quam', 'ut', 'tutor', 'et', 'ha', 'bens', 'gubernacionem', 'seu', 'ballum', 'fratrum', 'et', 'sororum', 'suorum', 'in', 'minori', 'etate', 'constitutorum,', 'possessionem', 'aliquorum', 'bonorum', 'mobi', 'lium', 'et', 'inmobilium', 'apprehenderit,', 'quorum', 'possessionem', 'Thomas', 'juvenis', 'pater'],
'tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0],
'language': 'FR'
}Each sample specifies key, start_token_id, score, tokens, tags, and language. The key links the sample to the text file the sequence was taken from. start_token_id is used to merge the sequences, so we get predictions for all tokens in the text. This way, performance can be calculated for complete texts instead of sequences. score (normalized editdistance) is used for selecting high qualitity data. For the first experiment, sequences with a normalized editdistance > 0.3 were removed from the train and validation sets (but not from the test set!). tokens and tags contain the data that is used to train the classifier. language was not used for the first experiment.
The model
The code for training the model can be found in this notebook. After loading the dataset, there is one more detail that needs to be taken care of. BERT uses subword tokenization, while the dataset contains labels for complete words. Also, BERT tokenizers add special tokens [CLS] and [SEP]. This means that after BERT tokenization, the input labels don’t match the tokens anymore, e.g.,
Input sequence (and labels):
{
'tokens': ['This', 'is', 'a', 'cxample...']
'tags': [0, 0, 1, 1]
}Because the ICDAR dataset is multilingual, I selected bert-base-multilingual-cased as a base model. Tokenized with the bert-base-multilingual-cased tokenizer the sequence becomes:
['[CLS]', 'This', 'is', 'a', 'c', '##xa', '##mp', '##le', '.', '.', '.', '[SEP]']To be able to train the model, the labels will have to be realigned. The Hugging Face task guide on token classification contains an example tokenize_and_align function for doing so. A slightly adapted version was added to the ocrpostcorrection package. This function is a partial, allowing the tokenizer to be instantiated separately. This makes it more convenient to apply it to a dataset using the Dataset.map function, because there is no need to add a lambda function. To use the function, do:
from ocrpostcorrection.token_classification import tokenize_and_align_labels
tokenized_icdar = icdar_dataset.map(tokenize_and_align_labels(tokenizer), batched=True)After preparing the dataset, and instantiating a data collator, model and trainer, training can start. For this experiment, the model was trained on Google Colab, using the following training arguments:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='choose/your/own/output/directory',
evaluation_strategy='epoch',
num_train_epochs=3,
load_best_model_at_end=True,
save_strategy='epoch',
per_device_train_batch_size=16
)The best model came from epoch 2. For this model, training and validation loss were 0.254 and 0.291, respectively.
Results
The code that was used to determine the performance of the model can be found in this notebook. Performance is calculated using the competition evaluation script. This script expects input in the form:
{
"<language>/<set>/<number>.txt":
{
"0:1": {},
"4:2": {},
...
}
...
}The first number in the keys for a text represents the start index of the OCR mistake. The second number is the number of (input) tokens that are incorrect. The evaluation script calculates precision, recall and F-measure on the token level.
It takes quite some steps to transform the (sub)token-level predictions that the model provides as output into the format accepted by the evaluation script. First, predictions for subtokens are merged into predictions for InputTokens. An InputToken is considered an OCR mistake if at least one subtoken is predicted to be an OCR mistake. Next, sequences of InputToken-level predictions are merged into predictions for an entire text. If predictions for overlapping InputTokens differ, it is considered as an OCR mistake. Finally, the predictions for individual tokens are translated to character offset:number of tokens-pairs. The predictions2icdar_output function is available for this conversion process. It takes as input the tokenized test set, the predicted labels, the tokenizer, and a dictionary with <file name>: Text pairs, and returns the expected ICDAR output format:
from ocrpostcorrection.utils import predictions2icdar_output, predictions_to_labels
output = predictions2icdar_output(tokenized_icdar['test'],
predictions_to_labels(predictions),
tokenizer,
data_test)When saved to a JSON file, the output dictionary can be used to calculate performance using the runEvaluation function. The runEvaluation code was taken from the original evalTool_ICDAR2017.py (CC0 License) via Kotwic4/ocr-correction. In addition to the JSON file, the function requires the (path to the) test set as input. The function creates a csv file containing precision, recall, and F-measure for all texts in the test set. The following table contains the mean results grouped by language.
| Language | Precision | Recall | F-measure | F-measure CCC (2019 competition winner) |
|---|---|---|---|---|
| BG | 0.88 | 0.67 | 0.74 | 0.77 |
| CZ | 0.81 | 0.55 | 0.64 | 0.70 |
| DE | 0.98 | 0.89 | 0.93 | 0.95 |
| EN | 0.85 | 0.54 | 0.62 | 0.67 |
| ES | 0.91 | 0.46 | 0.59 | 0.69 |
| FI | 0.89 | 0.77 | 0.82 | 0.84 |
| FR | 0.81 | 0.49 | 0.59 | 0.67 |
| NL | 0.87 | 0.60 | 0.66 | 0.71 |
| PL | 0.89 | 0.70 | 0.77 | 0.82 |
| SL | 0.80 | 0.58 | 0.64 | 0.69 |
The last column of the table reports the mean F-measure for CCC, the 2019 competition winner. CCC outperforms the new model on every language, although, for some languages the difference is quite small. However, for a first attempt, I think the results are not bad at all!